Databricks is a California-based BI company. In this article, you’ll learn how to connect Peakboard to Databricks and retrieve some data.
Databricks offers a wide array of methods for accessing the data stored inside, in order to support any type of client. Because Peakboard supports ODBC drivers, using ODBC seems obvious. However, we will actually use the REST API endpoint to submit queries and receive data.
While configuring ODBC is possible, it’s quite complicated. On the other hand, using the method explained in this article is easy and straightforward. The system we’re using is a Microsoft-Azure-based Databricks instance.
Configure Databricks
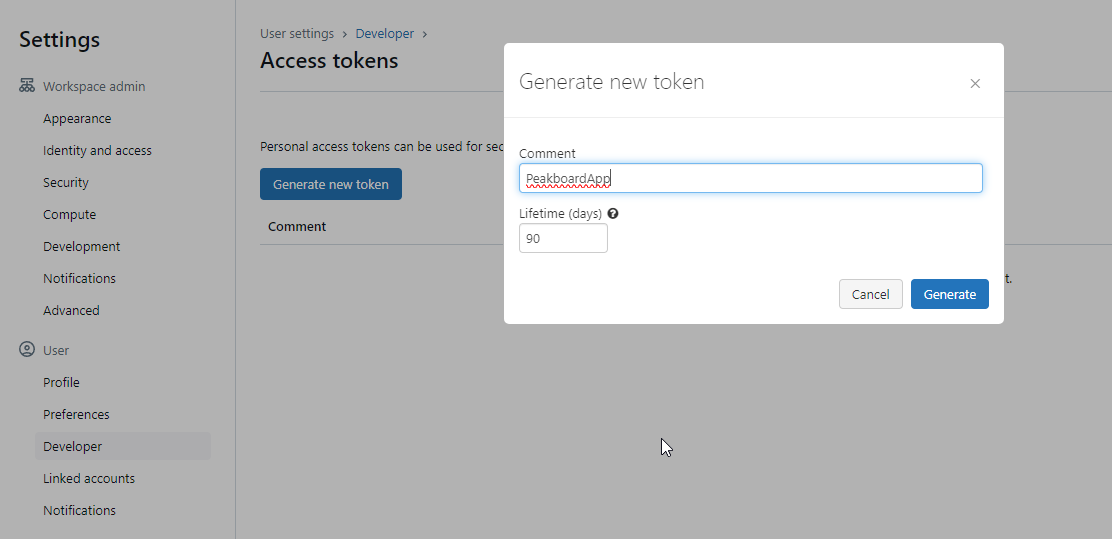
The REST endpoint and REST API are available by default. But before we can use them, we need to generate a token. To do so, we go to Databricks workbench > User settings > Developer > Access tokens > Manage > Generate token. We copy down the token for later use.
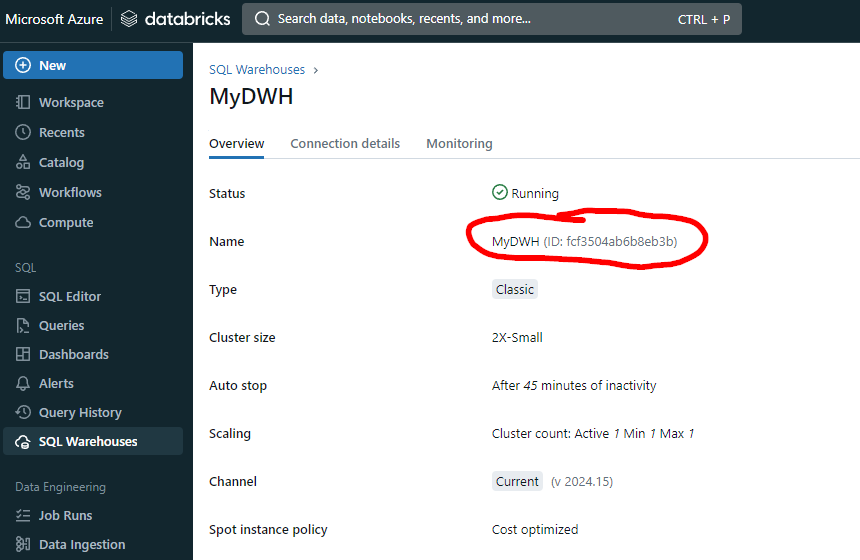
The second thing we need is the Warehouse ID of the Warehouse instance we want to access. We go to SQL Warehouses, and then click on the warehouse name. The Warehouse ID can be found under Name.
Set up the Databricks Extension
We will use the REST endpoint of Databricks to query the data. We can actually use the JSON data source to query the data and process. The tricky part is in the JSON response and the interpretation of the JSON string. It’s not easy, because the actual data, data-description-like datatypes, and other metadata, are stored in different places.
This problem is solved by the Databricks extension, which you can install with the click of a button. For information about how to install an extension, see the Manage extensions documentation.

Understand the Databricks REST Service
The Databricks instance comes with a REST webservice that exposes DWH functions. The endpoint we’re looking for is api/2.0/sql/statements/. So the whole URL looks something like this (depending on the user’s actual host name):
https://adb-7067375420864287.7.azuredatabricks.net/api/2.0/sql/statements/The query is done through a POST request containing a simple JSON with the DWH ID and the actual SQL statement. When referring to tables, we must always provide a qualified name with schema information. Here’s an example of a typical query:
{
"warehouse_id": "fcf3504ab6b8eb3b",
"statement": "select * from pbws.default.products"
}You can take a look at the statement execution function documentation.
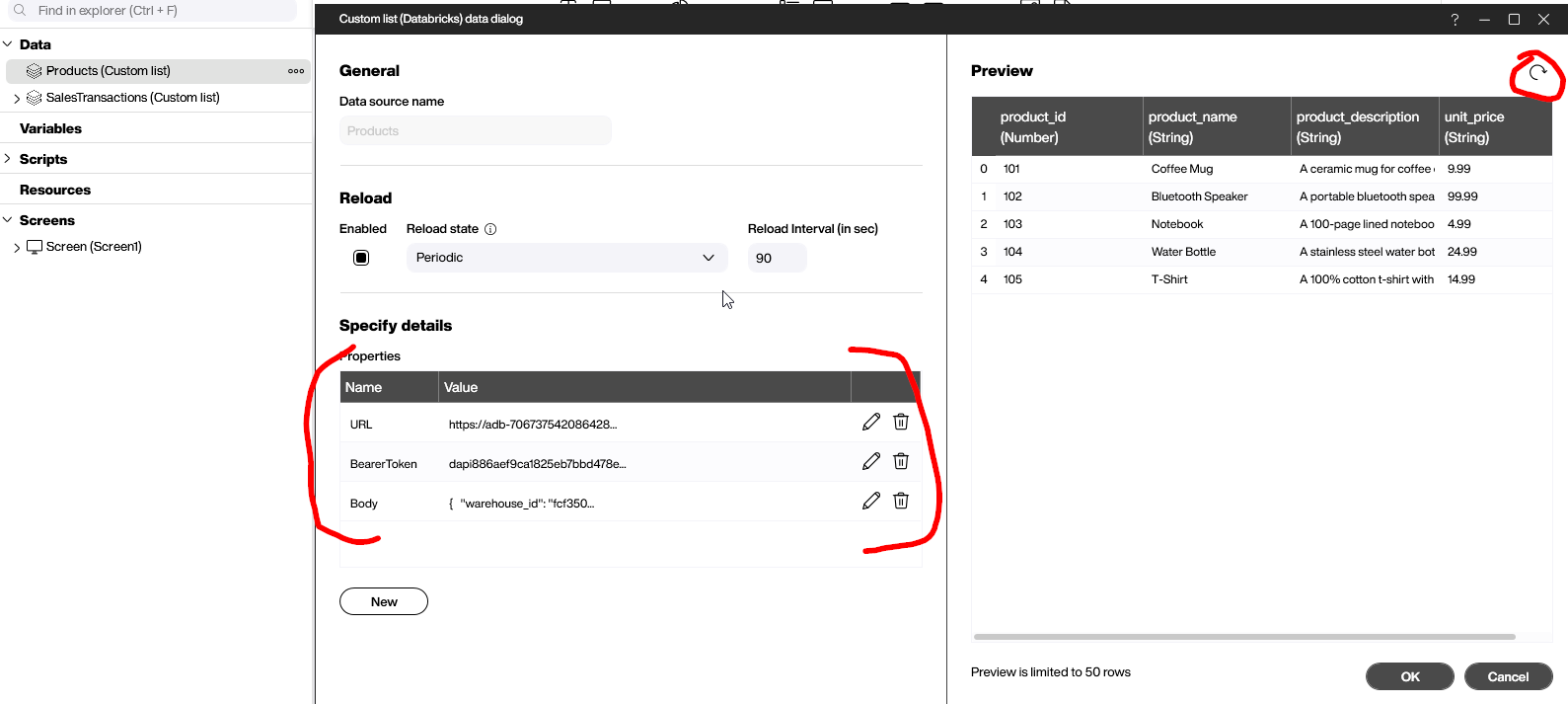
Set up the data source
We now have the URL, the access token (bearer token), and the JSON body with the SQL statement encapsulated. Now, it’s easy to fill the necessary parameters and execute the query:
Result and conclusion
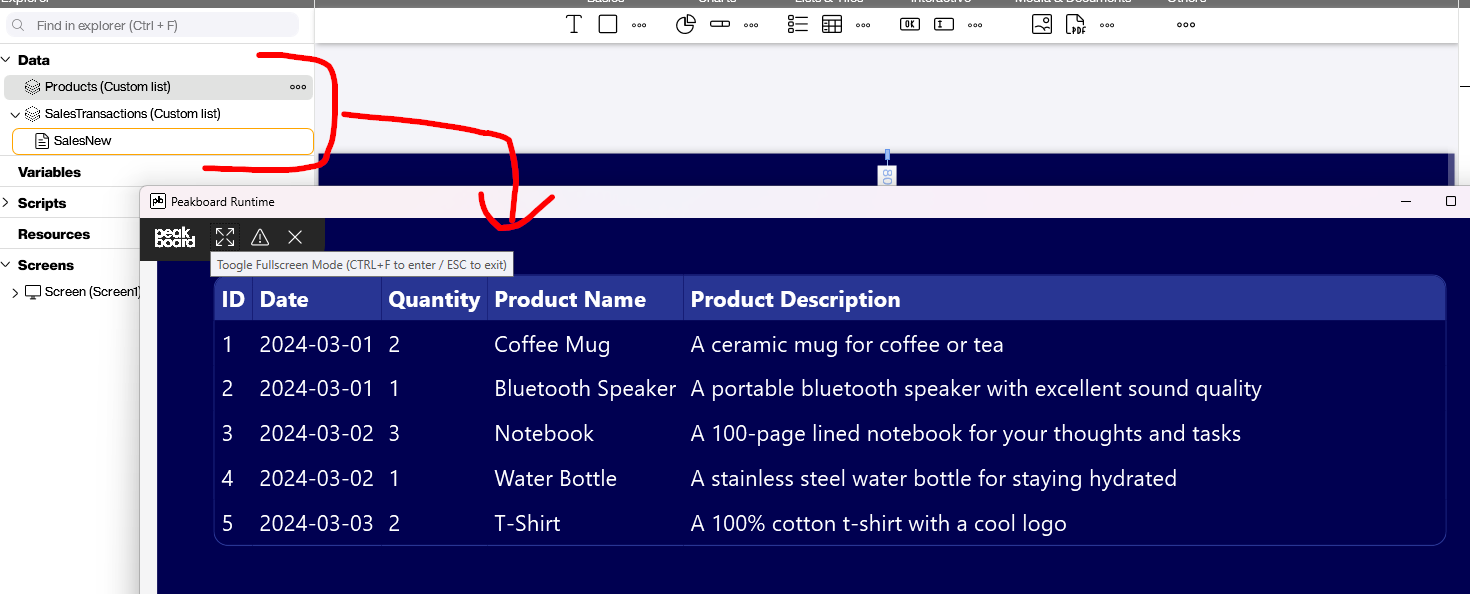
This article comes with an example PBMX file with two Databricks data sources (products and sales transaction) that are joined into a single table.
It might sound strange to not use the ODBC driver and stick to native REST calls, but in the real world, it turns out that the REST option is far easier to handle. Especially when there are additional complexities, like dynamic parameters, additional execution attributes, etc.