Loading a CSV file with Peakboard is straightforward—no need to write an article about that. But what about when you don’t know exactly which files to load, or if the data you’re looking for is spread out across multiple files? This is exactly the problem we will be solving today.
The scenario
Let’s say that every couple of seconds, an air conditioner writes a log entry to a CSV file in a shared directory. Each entry has a timestamp, temperature, and power consumption.
Here’s what the contents of the log files look like:
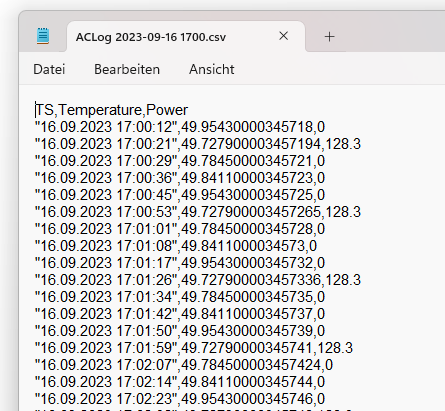
The tricky thing is, the AC starts a new log file every hour, and it gives it a dynamic name that contains the current date and time. So throughout the day, there will be multiple log files in the directory, like this:
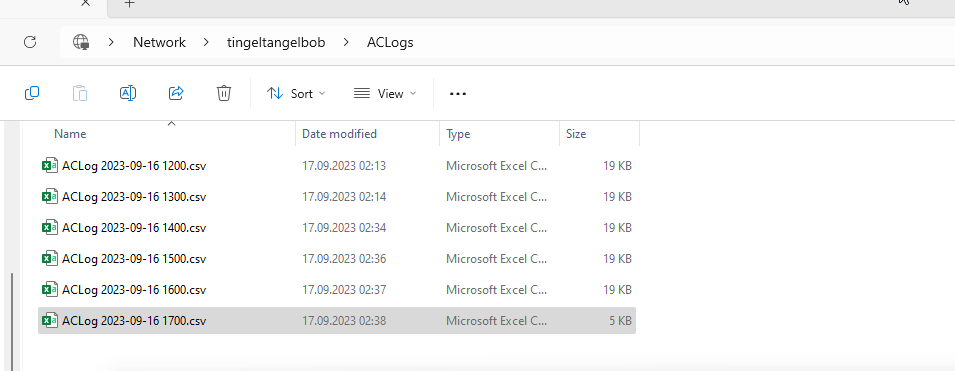
Now, let’s say we want to get a list of all log entries in the last 60 minutes. These entries will almost certainly span two log files. (The only time it wouldn’t is if the time is exactly XX:00:00.)
So, we will need to read from two log files: the current log file and the previous log file.
The plan
Here are the steps we will follow:
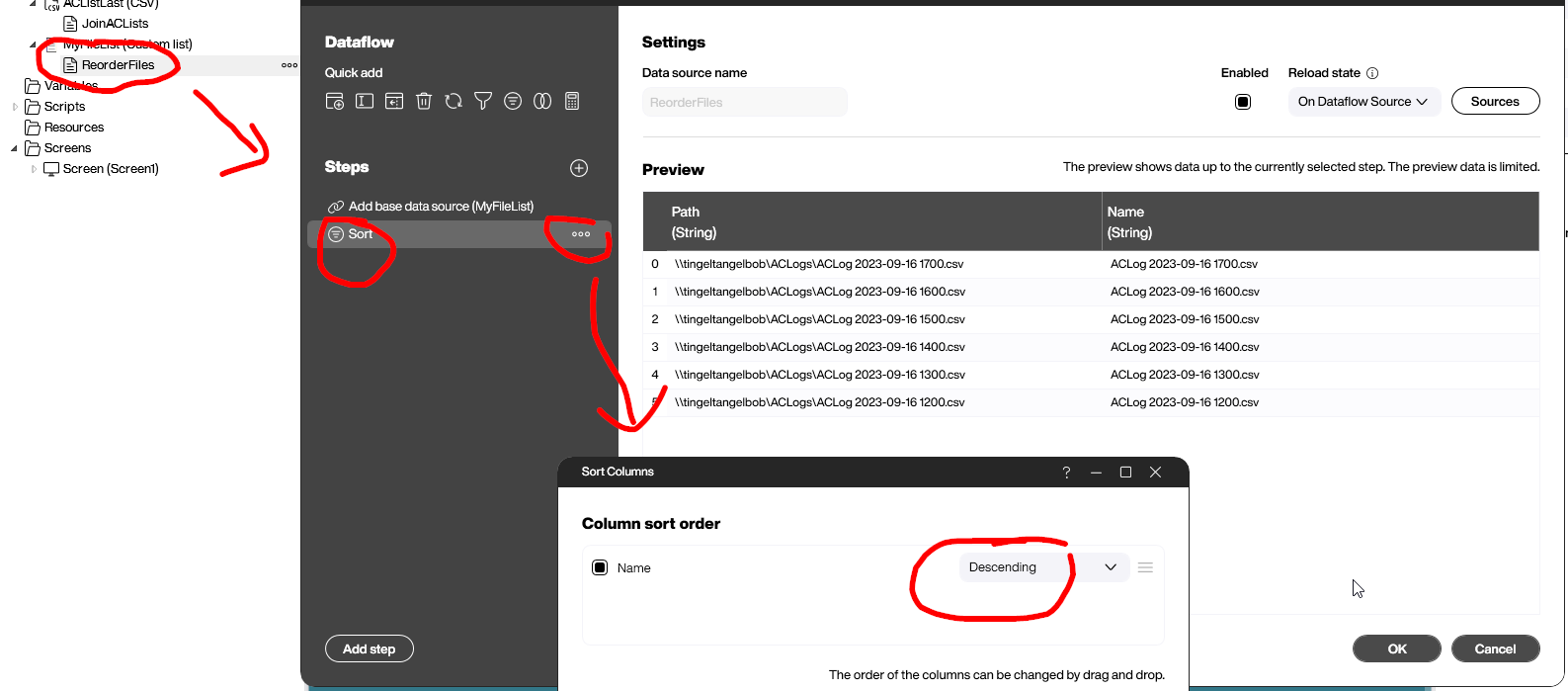
- List all the log files in the shared directory. Sort them in descending order by name, so that the current log file is the first file, and the previous log file is the second file.
- Load all log entries from the current log file.
- Load all log entries from the previous log file.
- Join the data from the two log files and sort the result in descending order, by timestamp.
Load the available files
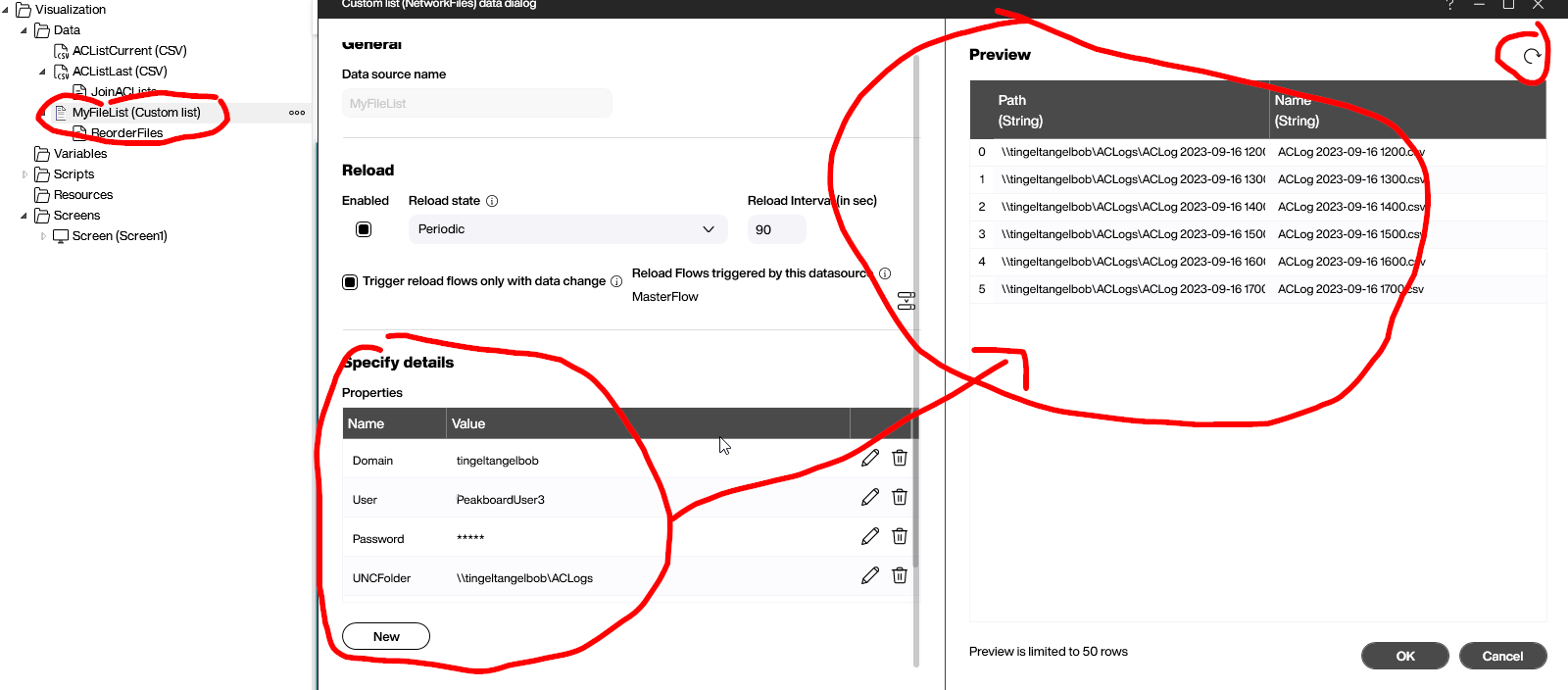
For Peakboard to query all the log files in the shared directory, we need to install the Network Files extension.
The configuration for the network file list needs the credentials to access the folder (domain, username, and password), as well as the actual UNC path.
We trigger the data load to make sure it works.
Now, we need to make sure the file list is ordered correctly. So we add a data flow to the data source. The data flow has only one step, which sorts the list in descending order.
Setting up the data sources
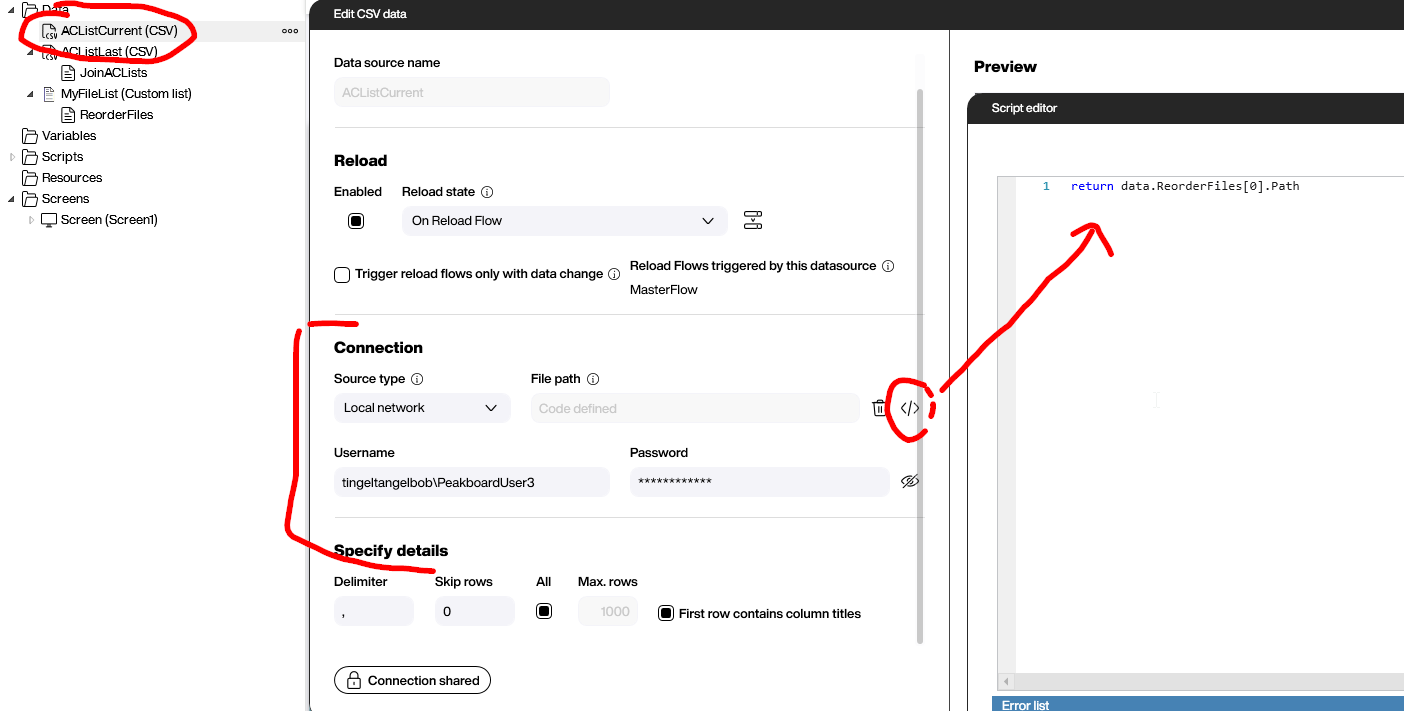
We need two CSV data sources that look very similar. The first one, ACListCurrent, uses the same credentials that we used for the network file list.
The trick here is to not have a static file name, but rather use a one-line LUA script. This script gets the file name from position 0 from the ReorderFiles data flow we created in the last step.
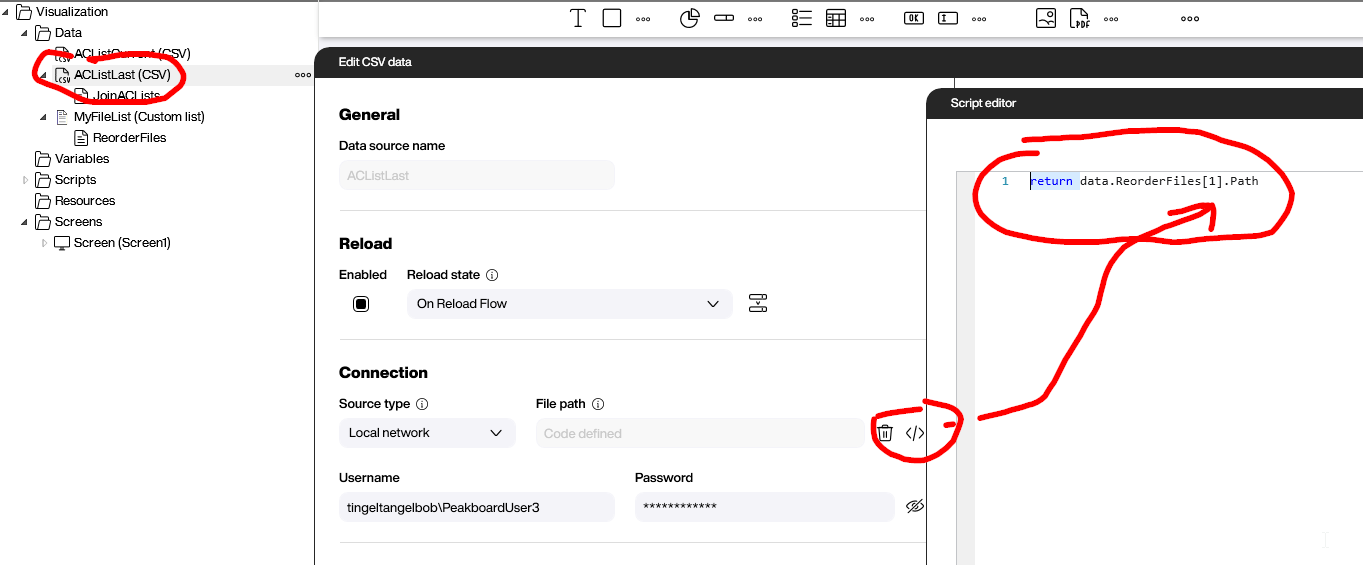
We do the same thing for the ACListLast data source, except we point to position 1, which is the second entry of the file list.
Joining the data sources
The next step is to join the data sources from the last two steps.
We do this with a data flow below the ACListLast data source. The first step is to join ACListLast with ACListCurrent. In database terminology, it would be called a “union join.”
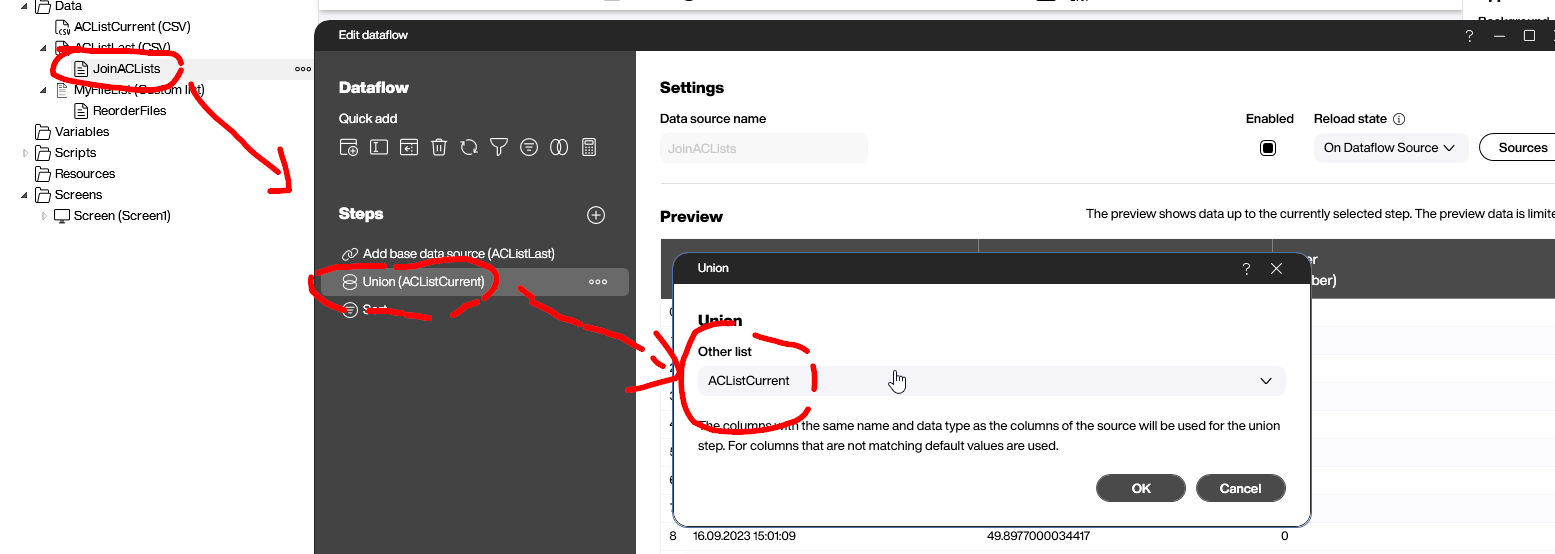
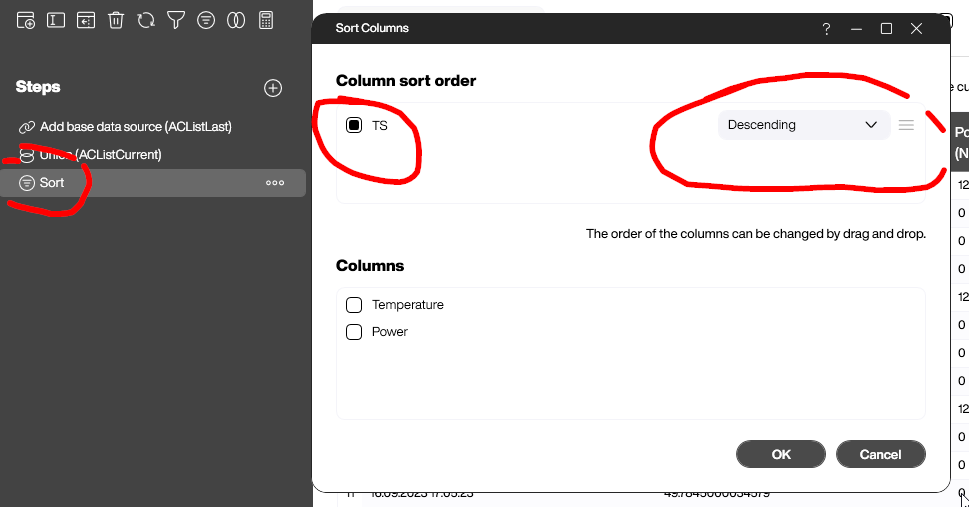
After joining, we need to sort the data by the timestamp column, TS, in descending order. That way, the latest entries are on top.
Ensuring the right order with a reload data flow
To get the correct final result, we must make sure that the steps outlined above happen in the right order. For example, it doesn’t make sense to load a file before we know which file to load by querying the network file list.
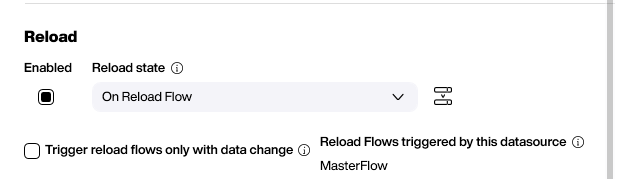
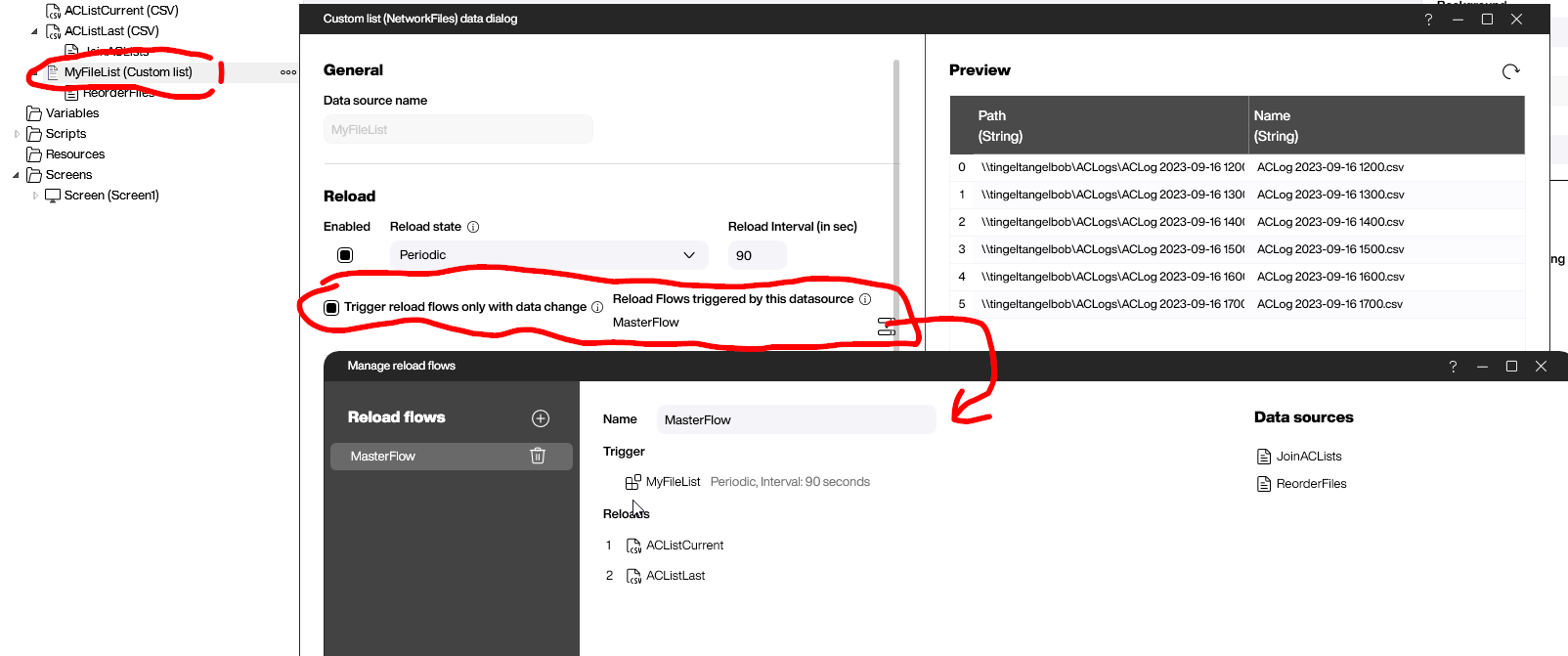
To ensure the correct order, we use a reload data flow. This way, the data flows are not triggered independently, but rather through the reload flow. To do this, we set the Reload state to On reload flow.
After accessing the design of the reload flow (let’s call it MasterFlow), we can ensure that everything happens in this order:
- The file list is executed.
- The file-reading data sources reload.
The data flows below a data source are triggered automatically as part of the original data source. That’s why only the data source, but not the data flows, is a part of MasterFlow.
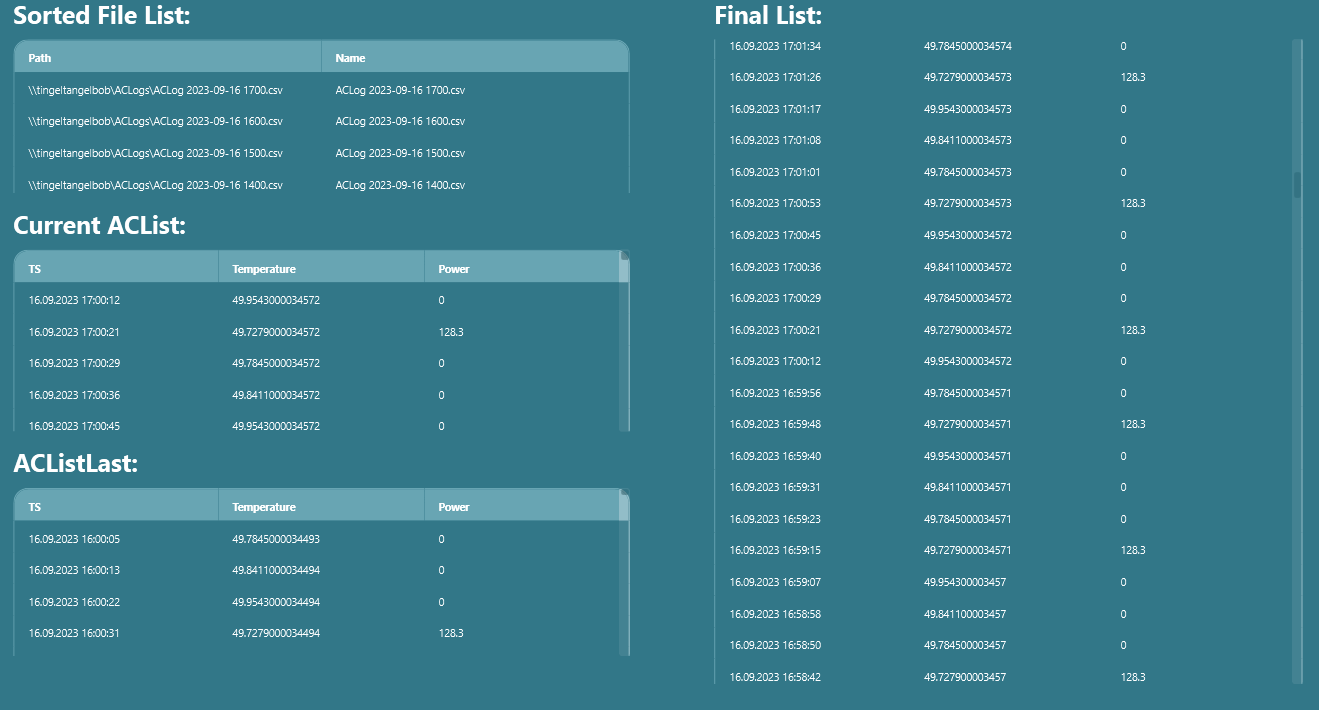
Result and conclusion
The following screenshot shows the result of the process explained earlier. The first table in the top-left corner shows the list of log files sorted by date, in descending order. Below that table are the contents of the two log files we selected (the current and previous log files).
On the right side is the final result set, which contains entries from both hours—one starting from 17:00 (the current log file) and one starting from 16:00 (the previous log file).