
In today’s article, we will learn how to use SQL statements with functions for aggregation and table join, in order to extract data from Peakboard Hub tables.
We’ve also covered various topics related to Peakboard Hub lists in other articles (check out the links at the bottom of this page).
Why would you want to use aggregation / joins when you can use data flows for data manipulation?
The most obvious reason is to limit network traffic. Let’s say you have 10k+ rows of sensor data, and you want to get the number of rows. Then it doesn’t make sense to download all 10k+ rows just to count them. Instead, you can let Peakboard Hub do the counting, and just download one row, which contains the result.
The same is true with table joins: Let’s assume you have orders and order lines. The order has a date column. But you want to see the order lines of the order on a specific date. Of course, you could download all orders and all order lines, join them, and throw away all order lines that do not belong to orders on your desired date. Or, you can just use a table join to solve this problem on the source side, to avoid transferring too much data over the network.
Aggregate data by using aggregate functions
Let’s take a look at an example of how we can aggregate data by using aggregate functions.
The basis of this example is a simple table of sensor data. Specifically, it’s a list of temperature values. We have two columns:
- TS - the date and time when the temperature was taken
- Temperature - the actual temperature
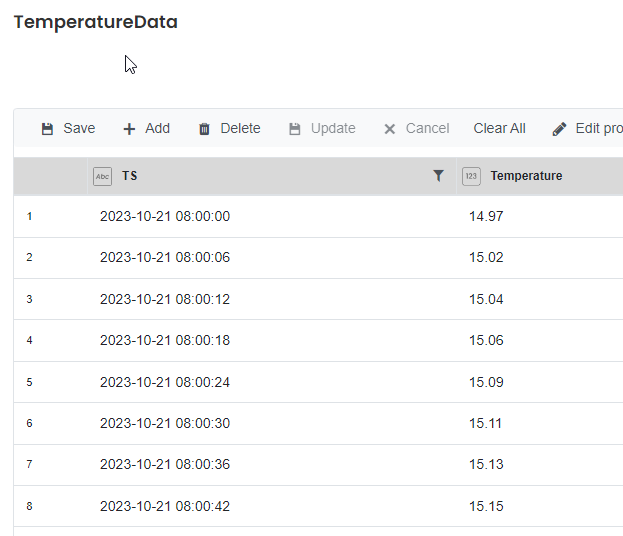
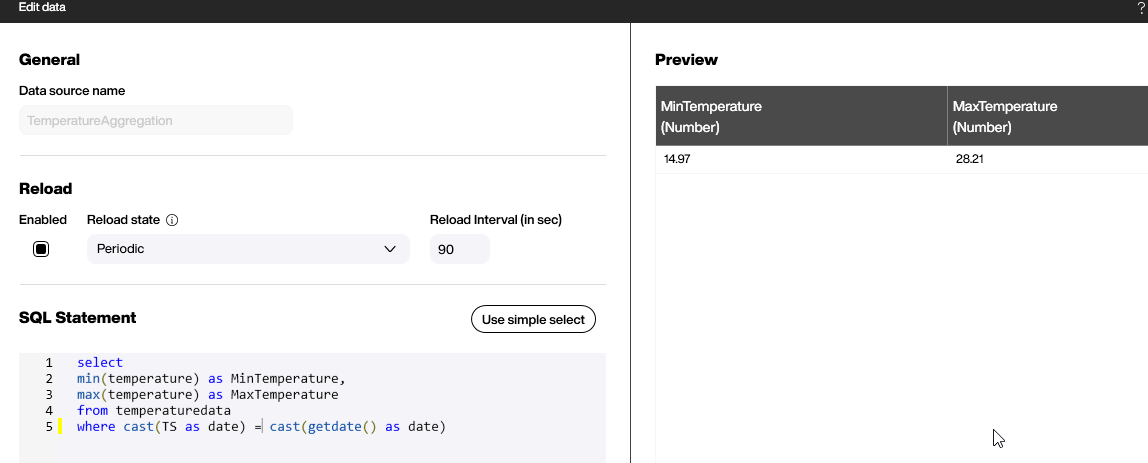
Let’s assume we are not interested in all the data. The only thing we want to know (and present on our dashboard later) is the maximum and the minimum temperature that was recorded today. To do that, we can give this SQL statement to the Hub:
select
min(temperature) as MinTemperature,
max(temperature) as MaxTemperature
from temperaturedata
where cast(TS as date) = cast(getdate() as date)To use direct, plain SQL in the Peakboard Hub List data source, you need to activate the SQL mode by clicking on the “Select with SQL” button:
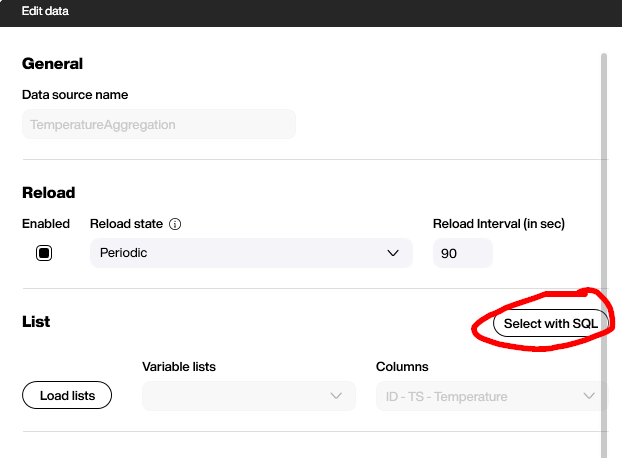
Then, you can use the above statement and check your result on the right side. Now, you have condensed thousands of rows down to the two numbers you’re interested in:
Joining Peakboard Hub lists
Now, let’s take a look at how we can join two Peakboard Hub lists.
In this example, we have a very simple relational connection between two tables:
-
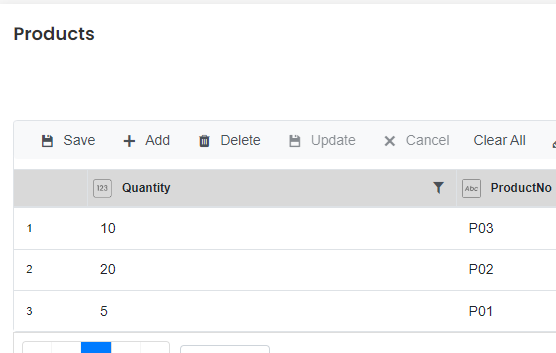
“Products” contains the products we have in stock. It has a column for the product number, and a column for the quantity of that product in the warehouse.
-
“ProductTexts” contains a brief product description for each product number, in different languages (English, German, and Chinese).
Here’s the “Products” table:
And here’s the “ProductTexts” table:
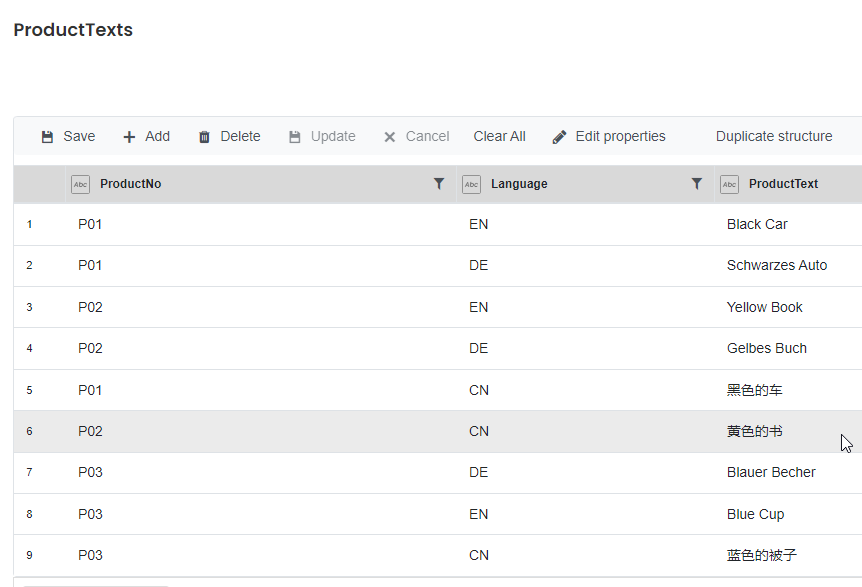
In our Peakboard application, we want a single table that contains our current stock quantities for each product and the German description texts. We can do that with this SQL statement:
select p.ProductNo, Quantity, Producttext
from
Products as p inner join ProductTexts as pt
on p.ProductNo = pt.ProductNo
where Language = 'DE'and here is the result:
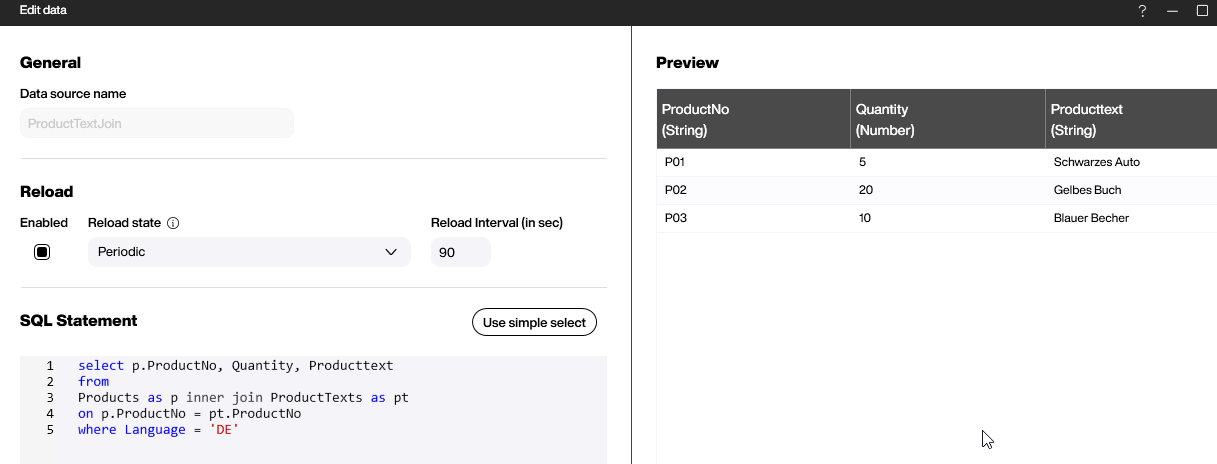
Conclusion
Preparing data in the source before bringing them into the Peakboard application is a wise choice, because it increases performance and limits network bandwidth. Beside Peakboard Hub lists (as shown in this article), this works with almost any database or SQL-based environment. You should consider this option every time you design a new data source for a Peakboard project.